国家生态科学数据中心提出基于机器学习随机森林模型提高国家尺度植被碳密度估算精度的方法
不同陆地生态系统模型在估算国家尺度植被碳密度存在明显的差异,为评估区域碳源汇带来了不确定性。多模型模拟结果之间可能存在非线性的依赖关系,但是常见的多模式集成的方法仅简单的处理了这种联系。机器学习的随机森林方法具有充分挖掘变量之间非线性关系的优势。
中国科学院地理科学与资源研究所黄玫副研究员、王昭生博士等基于AVIM2、CEVSA2、BIOME-BGC、CLASS-CTEM-N、CLM4、CLM4VIC、DLEM、ISAM、TEMP6和TRIPLEX-GHG模型模拟的1982-2010年中国植被碳密度数据,结合野外调查的植被碳密度数据,利用机器学习随机森林方法构建了新的中国陆地植被碳密度的估算模型,重新估算了1982-2010中国陆地植被碳密度。与观测数据相比,随机森林多模型集成模拟结果仅低估了约0.2% (图1)。而传统的多模型平均的结果高估了约2%的中国区域植被碳密度。同时,泰勒模型比较结果表明,基于机器学习的模型模拟结果具有最小的标准差,最大的相关系数(图2a)。此外,随机森林多模型集成模拟结果与NDVI的年变化趋势较为一致,而多模型平均结果与NDVI的年变化趋势相反(图2b)。总之,随机森林多模型集成模型可以有效提高估算国家尺度陆地植被碳密度的精度,有助于减少大尺度植被碳储量估算的不确定性。本研究为集成多模型模拟结果减少碳估算不确定性提供了新的估算方法。
相关研究成果发表于英国生态学会老牌期刊Methods in Ecology and Evolution,相关数据见https://doi.org/10.12199/ecodb.00032。论文第一作者为王昭生博士和巩贺博士,通讯作者为黄玫副研究员。该研究得到中国科学院战略性先导科技专项、国家重点研发计划项目、国家自然科学基金以及青藏高原二次科考等项目的支持。
论文信息:
Wang, Z., Gong, H., Huang, M., Gu, F., Wei, J., Guo, Q., & Song, W. (2021). A multimodel random forest ensemble method for an improved assessment of Chinese terrestrial vegetation carbon density. Methods in Ecology and Evolution, 00, 1– 16. https://doi.org/10.1111/2041-210X.13729.
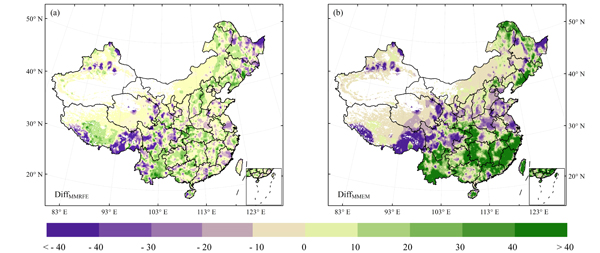
图1 (a)多模型平均植被碳密度与观测的植被碳密度之差;(b)本研究的模型与观测的植被碳密度之差(Mg C ha-1)
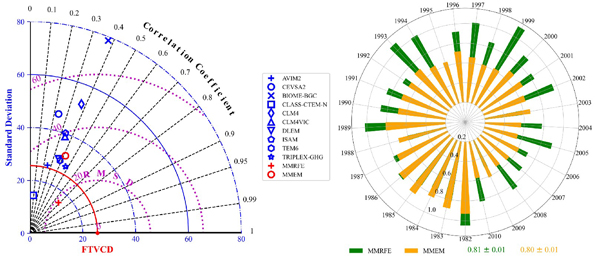
图2(a)观测与模拟的中国区域植被碳密度的泰勒图;(b)机器学习方法与多模型平均方法模拟的植被碳密度与NDVI相关系数比较
附件下载:
